
02.09.2020 Lesedauer ca. 11 Min.
Inhalt
Etablierte Unternehmen können auf große, wachsende und gut integrierte Datenbestände zugreifen. Darüber hinaus gibt es eine Vielzahl öffentlicher und kommerzieller Datenbanken, auf die nicht nur komfortabel per API zugegriffen werden kann, sondern die auch schon einen Teil der Auswertung übernehmen.
In der Praxis kommt man aber schnell an den Punkt, wo zur Auswertung gewünschte Daten nicht ausreichend oder gar nicht vorhanden sind. Hier kann es sich lohnen auch unstrukturierte Daten wie Bücher, Artikel oder eben Internetseiten in die Betrachtung einzubeziehen. Letztere sind durch HTML Tags und IDs zumindest teilweise strukturiert.
Begrifflichkeit
Webcrawling wird häufig mit großen Suchmaschinen wie Google in Verbindung gebracht, deren Webcrawler das Internet indizieren. Ein Crawler startet mit einem bekannten Stamm an Internetseiten und sammelt erst auf diesen bereits bekannten Seiten Links zu weiteren, vorher noch unbekannten, Webseiten. Auf diese Weise erreicht der Crawler jede Webseite, die auf irgendeine Weise in die Link Struktur des Internets eingebunden ist. Dabei muss er so robust programmiert sein, dass auch unbekannte Seiten zuverlässig verarbeitet werden können.
Webscraping beschäftigt sich mit der Extraktion von Informationen von einer Webseite. Das muss nicht automatisiert passieren - ist es aber meistens. Jeder Webcrawler muss Informationen von einer Webseite extrahieren und verarbeiten, ist also auch ein Scraper. Jedes nicht triviale Scraping-Unterfangen navigiert zwischen mehreren URLs und hat so auch eine Crawling-Komponente. Im Folgenden verwenden wir der Einfachheit halber nur den allgemeineren Begriff “Webcrawling”.
Anwendung
Nehmen wir als praktisches Beispiel das Frorum. Hier gibt es viele interessante Artikel, aber weder einen Newsletter noch einen RSS-Feed, um auf dem Laufenden zu bleiben. Im Folgenden nehmen wir das selbst in die Hand und nutzen die Gelegenheit, um die grundlegenden Techniken des Webcrawlings beispielhaft gemeinsam durchzugehen. Am Ende steht ein Programm, dass den Inhalt des Frorums systematisch ausließt und in einer Datenbank speichert. Das entspricht einem minimalem Webcrawler. Dieser kann leicht erweitert oder für andere Webseiten angepasst werden. Mit ein wenig zusätzlicher Logik könnten wir das Programm in einem gewissen Zeitintervall automatisch laufen und uns informieren lassen, sollte es einen neuen Artikel geben. Genauso wäre es auch möglich die gesammelten Daten nach gewissen Begriffen und regulären Ausdrücken zu durchsuchen. Der Sourcecode den wir in diesem Artikel erarbeiten steht auch vollständig hier zur Verfügung.
Für komplexere Webcrawler wird die Verarbeitung der gewonnen Daten immer wichtiger. Sören Schmidt beschäftigt sich in seinem Artikel Bigdata-Streaming mit genau diesem Thema: Wie kann hoher Datendurchsatz mit gleichzeitig geringer Latenz in der Verarbeitung großer Datenmengen bestmöglich kombiniert werden.
Setup
Zuerst brauchen wir eine Datenbank, um die Ergebnisse des Webcrawlers dauerhaft zu speichern. Für kleine Projekte oder zum Testen und Entwickeln kann man SQLite gut einsetzen. SQLite ist als dateibasierte Datenbank schnell einsatzbereit, ist aber aus dem gleichen Grund weniger skalierbar und nicht einfach in einem Netzwerk einzusetzen. PostgreSQL ist ein Datenbankserver mit integrierter Nutzerverwaltung und bietet außerdem eine fast perfekte Abdeckung des SQL-Standards. Wir werden hier eine Postgres Instanz verwenden. grundsätzlich gilt aber jede SQL Datenbank, die man gut kennt, ist eine gute Wahl.
Für die Datenverarbeitung nutzen wir das im Bereich Data Science sehr populäre Python3. Neben einer umfassenden Standardbibliothek bietet Python ein ausgereiftes Ökosystem von externen Bibliotheken, dem Paketmanager pip und Bindings zu anderen Programmiersprachen wie C. Hier einige Beispiele:
-
Pandas ist eine Bibliothek mit Datenstrukturen und Funktionen zur Verarbeitung von multi-dimensionalen Matrizen. Die wichtigste Datenstruktur ist dabei der DataFrame. Für einen Webcrawler ist die Funktion
read_html()sehr interessant. HTML Tabllen lassen sich mit ihr leicht und effizient auslesen. -
TensorFlow ist eine hardwarenahe Plattform für maschinelles Lernen. Der Zugriff auf die C++ Kernfunktionalität von TensorFlow erfolgt entweder direkt per Python Code oder über weiter abstrahierende Frameworks wie Keras. Mit der Funktionalität von TensorFlow kann ein Webcrawler auch Daten wie die semantischen Bedeutung von Webseiten oder den Inhalt von Bildern erzeugen und verstehen.
-
Jupyter Notebooks bietet die Möglichkeit Python Code in Echtzeit auszuführen, anzupassen und ihn mit Markdown Text und Visualisierungen in einer Datei zusammenzufassen und zu teilen. Das ist insbesondere in der Lern- und Entwicklungsphase eines Webcrawlers und für die weitere Analyse der gewonnenen Daten praktisch.
Datenbank
Nach der Installation von PostgreSQL können wir eine Datenbank “frorum_db” aufsetzen und einen Datenbanknutzer “frorum” erstellen:
createuser frorum
createdb frorum_db
Anschließend öffnen wir das Postgres Kommandozeilen Interface mit psql und konfigurieren die Datenbank mit Standard SQL:
ALTER USER frorum WITH ENCRYPTED PASSWORD 'sicheresPasswort';
GRANT ALL PRIVILEGES ON DATABASE frorum_db TO frorum;
ALTER DATABASE frorum_db OWNER TO frorum;
Mit \l vergewissern wir uns das alles geklappt hat und schließen psql mit \q. Die Datenbank ist jetzt bereit und kann von uns bzw. unserem Code befüllt werden.
Python
Um eine einheitliche Entwicklungsumgebung auch auf mehreren Maschinen zu gewährleisten, nutzen wir einen Umgebungsmanager. Wir installieren pipenv und erstellen eine neue virtuelle Umgebung:
pip3 install pipenv
pipenv --python 3
pipenv erstellt ein Pipfile, in dem alle benötigten Pakete aufgelistet sind. Momentan steht da nur Python 3.8 drin. Um uns das Parsen von HTML-Dokumenten zu erleichtern, fügen wir noch BeautifulSoup4 und lxml hinzu. Um die Postgres-Datenbank per Python Code zu steuern, brauchen wir noch das passende Interface psycopg2. Anschließend können wir die virtuelle Umgebung starten:
pipenv install bs4 lxml psycopg2
pipenv shell
Erforschung
Um einen ersten Eindruck zur Struktur der Ziel-Webseite zu bekommen, bietet sich das Inspektor-Tool eines Browsers an. Hier sehen wir, dass die Beitragsliste als Flexbox Layout angelegt ist und jedes Element dieser Tabelle ein div-Tag mit class="mdl-card ..." ist.
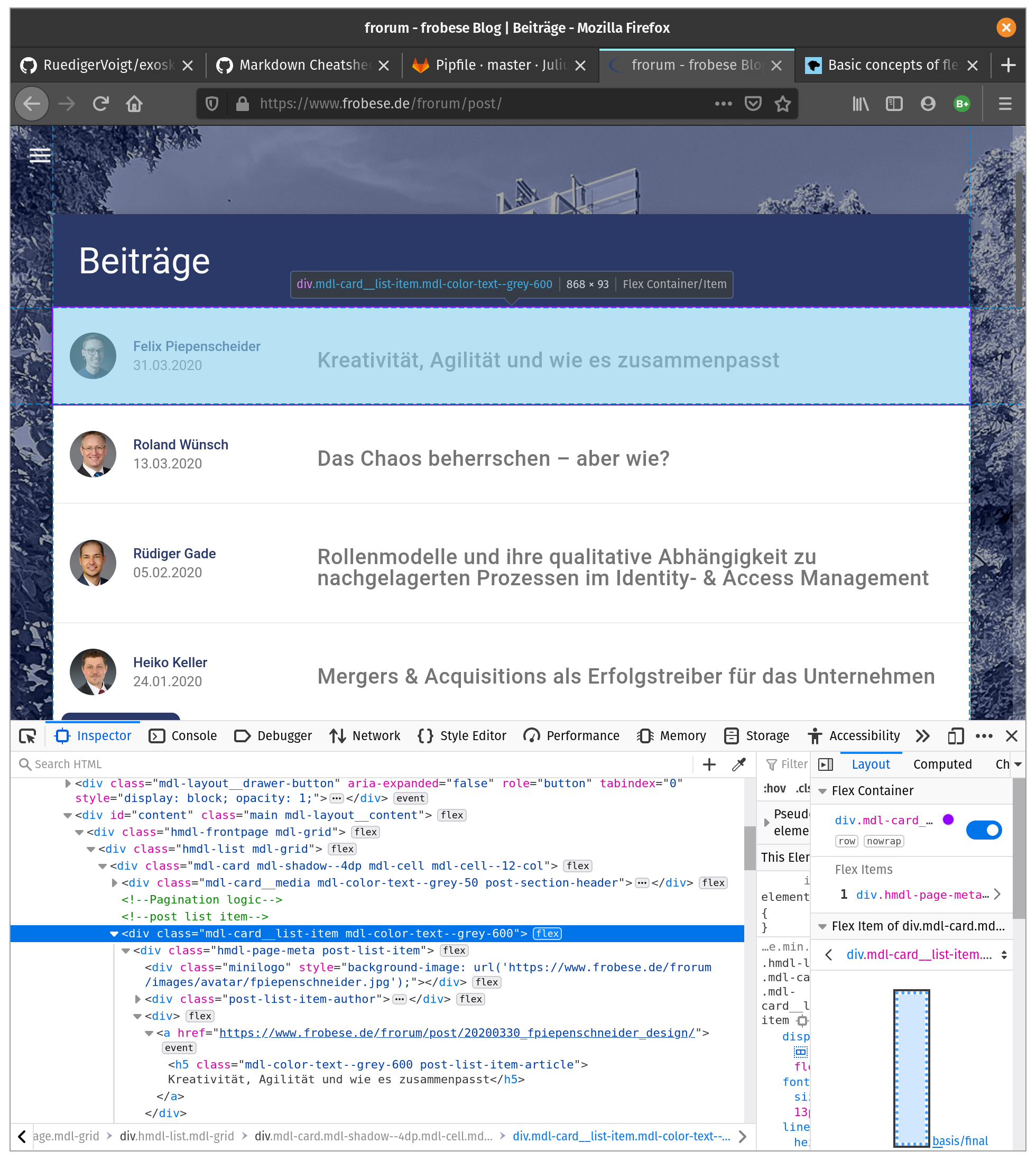
Zur weiteren Erforschung installieren wir Jupyter und starten ein neues Notebook:
pipenv install jupyterlab
jupyter notebook
Wenn wir den Sourcecode der Webseite speichern und direkt mit der HTML-Datei experimentieren, müssen wir nicht jedes mal eine Anfrage an den Server und unsere Datenbank stellen. Dann geht es auch für uns schneller. Nach einem interaktiven Spaziergang durchs DOM verstehen wir die Struktur der Webseite so gut, dass wir den relevanten Code in ein Python Skript übernehmen können. Das fertige Skript - nennen wir es index_frorum.py - sieht dann so aus:
import re
from bs4 import BeautifulSoup as bs
with open("./source/frorum.html") as page:
soup = bs(page, "lxml")
content = soup.body.find(id="content")
elements = content.find_all(class_=re.compile("card"))
articles = elements[2:]
for tag in articles:
title = tag.h5
link = title.parent.get("href")
print(title.string, link)
Jetzt bekommen wir alle Informationen, die wir brauchen. Statt diese aber einfach auf dem Terminal auszugeben, sollten wir alles in einer Datenbank speichern. So können wir auch später noch mit diesen Daten arbeiten Dazu melden wir uns zuerst am Datenbank-Server an:
psql -U frorum -d frorum_db
Dann erstellen wir eine Tabelle mit dem entsprechenden Schema:
CREATE TABLE index (
id SERIAL PRIMARY KEY,
title TEXT,
link TEXT
);
Wir kontrollieren mit \d index , ob alles geklappt hat. Das sieht gut aus! Jetzt können wir per Python eine Verbindung zur Datenbank aufbauen:
import psycopg2
conn = psycopg2.connect("dbname=frorum_db user=frorum password=sicheresPasswort")
cur = conn.cursor()
Jetzt ersetzen wir noch das abschließende print() in index_frorum.py durch einen Eintrag in die Datenbank:
cur.execute("INSERT INTO index (title, link) VALUES (%s, %s)", (title.string, link))
Damit haben wir alle Information, die für uns wichtig sind geordnet in der Datenbank hinterlegt. Wir haben also aus der HTML-Datei einer Webseite einen strukturierten Datensatz erstellt, mit dem wir leicht weiterarbeiten können. Als letzten Schritt fordern wir die HTML-Datei mit jedem Programmdurchlauf neu vom Server an. Das finale Skript sieht dann so aus:
import re
import psycopg2
import urllib.request as req
from bs4 import BeautifulSoup as bs
#### Verbindung zur DB herstellen
conn = psycopg2.connect("dbname=frorum_db user=frorum password=sicheresPasswort")
cur = conn.cursor()
cur.execute("SELECT version()")
print("Verbindung zu %s hergestellt" % cur.fetchone())
#### Verbindung zum Server herstellen und HTML-Datei laden
url = "https://www.frobese.de/frorum/post/"
response = req.urlopen(url)
page = response.read()
soup = bs(page, "lxml")
#### Navigation durchs DOM
content = soup.body.find(id="content")
elements = content.find_all(class_=re.compile("card"))
articles = elements[2:]
for tag in articles:
title = tag.h5
link = title.parent.get("href")
# Datensätze in die Datenbank schreiben
cur.execute("INSERT INTO index (title, link) VALUES (%s, %s)", (title.string, link))
print("==> %s eingefügt" % title.string)
#### Verbindung zur Datenbank schließen
conn.commit()
conn.close()
Ethisches Webcrawling
Wie bei fast allem gibt es auch hier Regeln, an die man sich halten sollte. Nicht nur als kategorischer Imperativ sondern auch um nicht unwissentlich eine DoS-Attacke zu starten. Jede Internetseite hat eine robots.txt Datei, die angibt, ob und wenn ja für welche Bereiche eine programmatische Verarbeitung erlaubt ist. Diesen codifizierten Willen der Seitenbetreiber sollte man befolgen. Auch ist es ratsam auf die Leistungsfähigkeit des Webservers zu reagieren und die Anzahl der eigenen Anfragen abhängig von der Reaktionszeit des Servers zu machen. So könnte der Webcrawler automatisch bei geringer Last (z.B. nachts) mehr Anfragen stellen und bei langer Reaktionszeit (länger als 100ms) die eigene Aktivität reduzieren.
Unabhängig davon kann es sinnvoll sein vorab mit dem Betreiber oder der Betrieberin der Webseite zu sprechen. Möglicherweise gibt es einfachere und für beide Seiten ressourcenschonendere Wege, an die benötigten Daten zu gelangen.
Alternative Datenquellen
Manchmal muss man sich gar nicht erst mit der Datenbeschaffung beschäftigen. Viele interessante Daten wurden schon von anderen gesammelt und dürfen frei verwendet werden. Hier sind die wichtigsten Quellen für diese Datensätze:
Fazit
Dieses Beispiel ist mit Absicht sehr einfach gewählt. Bei einem “echten” Datensammel-Job braucht man robusteren Code, der auch mit Exceptions und mit clientseitigen Javascript umgehen kann. Nur einige der möglichen Schwierigkeiten sind asynchron ladender Inhalt und Cookie-Banner, die dort auftauchen wo man eigentlich die Daten erwartet. Ein leistungsfähiger Crawler sollte parallel arbeiten können und trotztdem immer wissen welche Bereiche schon bearbeitet wurden und welche nicht. Und selbst der beste Crawler muss betreut werden. Das Internet ist schnelllebig und vollständig automatisiert geht es in den wenigsten Fällen.
Bei frobese bündeln wir alle Fähigkeiten rund um wissensbasierte Systeme - wie einen Webcrawler. Unser Dienstleistungsspektrum reicht dabei von der Konzeption solcher Systeme über die Beratung bestehender Projekte und Teams bis zur vollständigen Neuentwicklung aus einer Hand. Wir freuen uns schon jetzt auf spannende Projekte!
Referenzen
Über Julius Volland