
04.09.2019 Lesedauer ca. 5 Min.
Inhalt

Big Data
Während Du den ersten Absatz gelesen hast, ist vielleicht schon eine Minute vergangen - wie viele Daten in dieser Zeit 2018 produziert wurden sind kannst Du gut auf dem Bild erkennen. Was jedoch noch deutlich wichtiger als die Anzahl der Datensätze ist, ist deren Format. Es ist nicht vereinheitlicht die Daten liegen in strukturierter, semi-strukturierter und völlig unstrukturierter Art vor. Ähnlich vielfältig sind auch die Arten diese Daten zu verarbeiten. Das sind aber nur zwei Faktoren, die bei der Wahl der richtigen Bigdata-Architektur zu berücksichtigen sind.
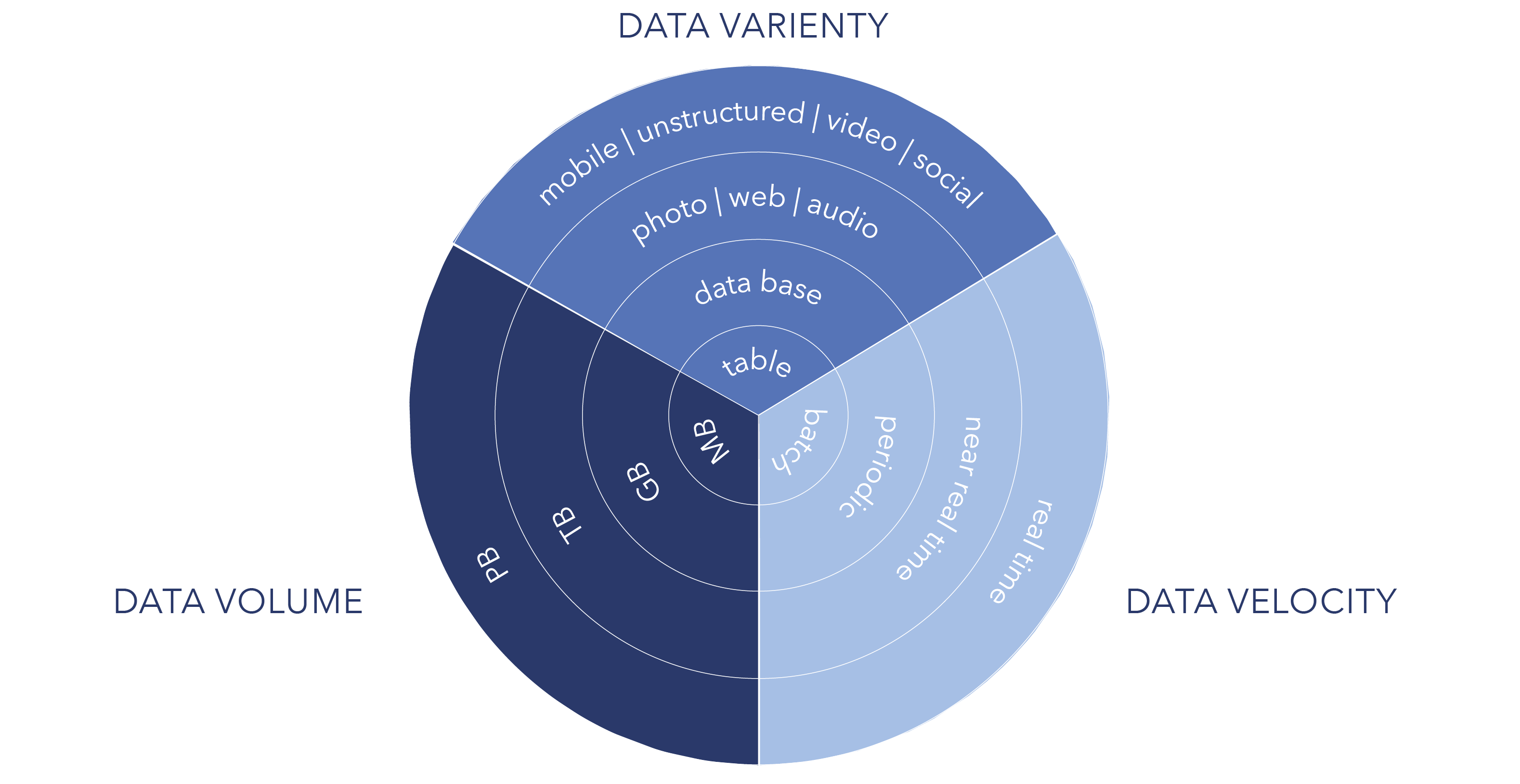
Um Bigdata generell zu definieren wird seit 2011 das drei V Modell von Gartner verwendet. Dies beschreibt 3 grundlegende Dimension die bis heute unumstritten sind.
Volume – Die allgemeine Größe der Daten, sofern sie für operative Systeme zu groß oder komplex werden sie zu verarbeiten oder zu analysieren.
Variety – Die oben erwähnte Vielfalt an Datenstrukturen. 80% der weltweiten Daten sind unstrukturiert - die Tendenz ist aufgrund des Internet of Things steigend. Für solche Daten reicht eine klassische Datewarehouse-Architektur mit relationalen Datenmodellen nicht mehr aus.
Velocity – Die Geschwindigkeit oder Schnelllebigkeit der Daten. Reicht es noch aus Daten im Tagesrhytmus zu verarbeiten oder brauche ich aktuellere Daten für meine Analysen? Besonders in der Industrie 4.0 sind Daten, die bis zu vierundzwanzig Stunden alt sind oft nutzlos.
Diese drei Dimensionen bilden die Grundlage von Bigdata. Es gibt daneben noch weitere Definitionen bis hin zu einem neun V-Modell. An diesen fünf weiteren Vs scheiden sich aber die Geister. Zwei zum Großteil akzeptierte weitere Dimensionen sind:
Validity – Die Sicherstellung der Datenqualität oder auch Glaubwürdigkeit der Daten. In Bigdata-Anwendungen sind Massen an Daten in allen Qualitätsstufen vorhanden, daher ist diese Dimension durchaus zu berücksichtigen.
Value – Der eigentliche unternehmerische Mehrwert. Die Investition in neue Bigdata-Architekturen soll sich ja rentieren, daher ist von Anfang an auch ein Auge auf den eigentlichen Unternehmensnutzen der Daten zu werfen.
Unser Fokus in diesem Artikel liegt aber mehr auf den grundlegenden Dimensionen, speziell der Velocity, da die Geschwindigkeit von Bigdata-Projekten in einem immer agiler werdenden Umfeld stetig an Bedeutung gewinnt.
Heutzutage reicht es in vielen Fällen nicht mehr aus seine Datenverarbeitung über Nacht laufen zu lassen und am nächsten Werktag mit Daten von gestern zu arbeiten. Der Wunsch nach tagesaktuellen Daten wird immer größer und realistischer. Eine Lösung dafür wäre eine Echtzeit- oder auch near-real-time-Datenverarbeitung, welche heutzutage oft als Streaming bezeichnet wird.
Mit der von Nathan Marz entworfenen Lambda-Architektur lassen sich solche Anforderungen bewältigen. Besonders die Video-on-Demand-Dienste wie Netflix oder auch Amazon Video greifen auf eine solche Architektur zurück.
Im Grunde erweitert die Lambda-Architektur die klassische Batch-Verarbeitungsschicht noch um einen sogenannten Speed-Layer. Um Daten gemeinsam auswerten zu können, wird noch eine dritte Schicht benutzt, der Serving Layer.
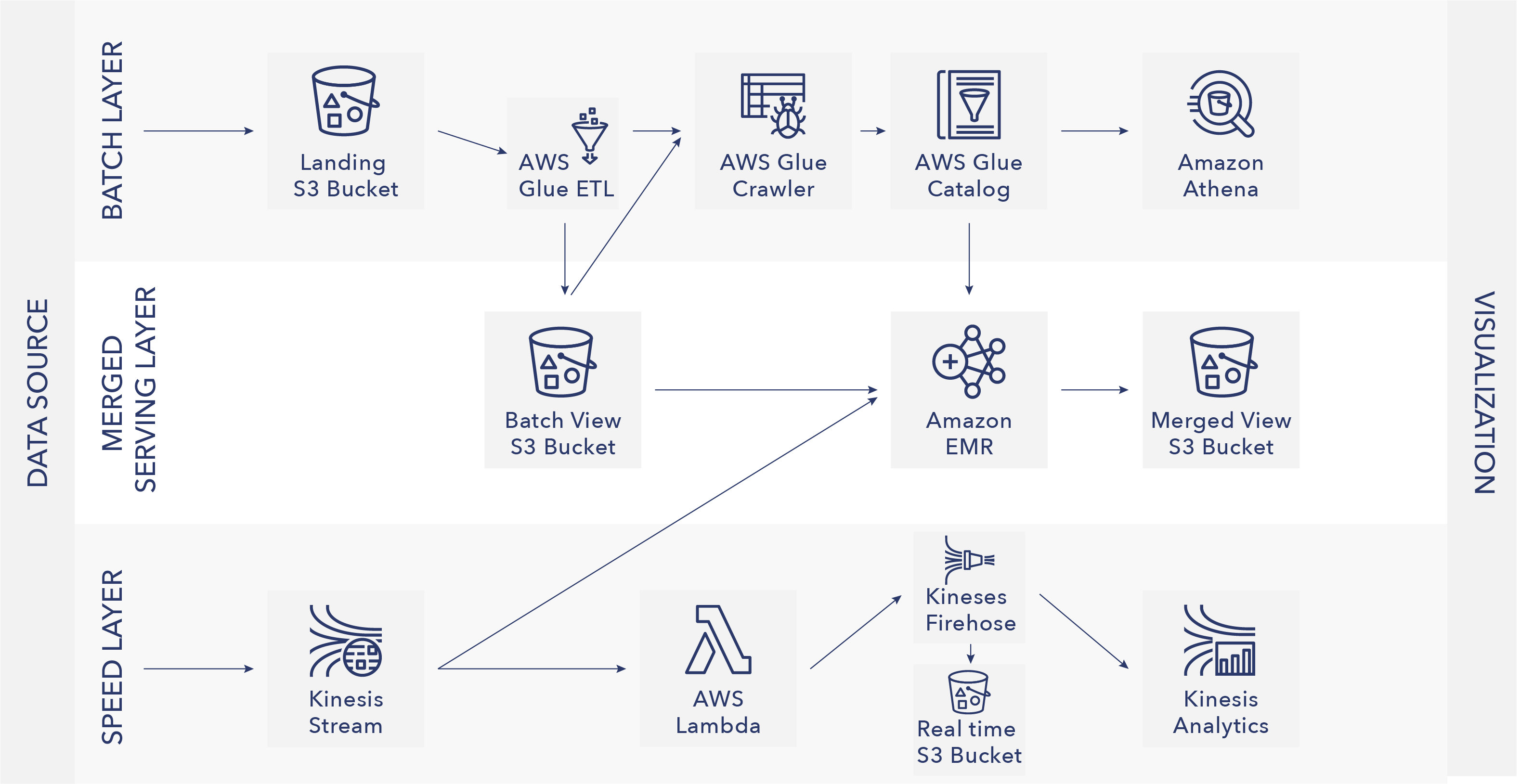
Batch Layer - Im Batch Layer sind alle Daten, die ausgewertet werden sollen, in redundanter Form vorhanden - dies kann je nach Projektumfang eine sehr große Menge sein. Im Batch Layer werden diese Daten auch aufbereitet und je nach Anwendungsfall aggregiert bevor sie in den Serving Layer wandern. Da diese Aggregation über alle Daten gemacht werden, kann dieser Vorgang viel Zeit in Anspruch nehmen.
Speed Layer – Um trotzdem Daten zur Auswertung bereitzustellen bedient der Speed Layer die Datenabnehmer sofort. Hier werden aber nicht alle Daten bereitgestellt, sondern nur die aktuellen werden temporär gespeichert und aggregiert bereitgestellt.
Serving Layer – Im Serving Layer läuft beides zusammen. Der Batch Layer stellt, sobald die Berechnungen durchgeführt sind, die Daten dem Serverving Layer bereit. Die vorhandenen Daten werden in dieser Schicht einfach überschrieben. Im nächsten Schritt werden die Daten mit denen des Speed Layers verbunden, um eine ganzheitliche Sicht für den Datenabnehmer zu erzeugen.
So können sich diese drei Schichten perfekt ergänzen, sofern man sie richtig nutzt. Es ist auch nur eine Architektur, entsprechende Softwarelösungen gibt es viele. Normalerweise werden Produkte aus dem Hadoop-Ökosystem gewählt, um eine solche Architektur umzusetzen. Für den Batch Layer in der Regel das klassische HDFS. Im Speedlayer fällt die Wahl auf Apache Spark oder Storm und der Serving Layer ist die eigentliche Datenbank. Je nach verarbeiteten Daten fällt die Wahl auf eine NoSQL Datenbank wie Cassandra oder hBase.
Fazit
Zusammenfassend lässt sich sagen, dass es nie die eine perfekte Architektur für alle Anforderungen gibt, man muss situativ entscheiden. Sollten wir also dein Interesse geweckt haben können wir sicherlich gemeinsam die für dich passende Lösung zum Datenhaushalt finden.
Quellen
Über Sören Schmidt